

Topic: 'Insight Finder': Reducing User Research from 3 Weeks to 30 Minutes — What to Delegate to AI and What Not To Speaker: Lee Se-wang - Nexon Korea Field: User Research Automation, Data, Artificial Intelligence Recommended for: Game designers, PMs/POs, producers, UX researchers, service operations managers, and anyone who makes decisions based on user feedback
Tags: #NDC26 #Research #UX
[🚨 Session Topic] This session shares the design process and key decision-making behind 'Insight Finder,' an AI-based analysis platform developed to simultaneously boost the speed and depth of user research.
While listening to the user's voice is increasingly vital in game development, analyzing that feedback and extracting meaning remains time-consuming. Organizing a single survey can take days, and cross-referencing groups can stretch the process to weeks. Nexon solved this with an 'AI-based research analysis platform.'
At NDC 2026, Lee Se-wang of the Nexon Korea Game UX Analysis Team unveiled 'Insight Finder,' a platform he planned and developed, explaining how he redefined user research tasks during this massive AI transition.
The core of the presentation can be summarized in one sentence: applying AI to research analysis is not just about simple automation, but about redefining the process through three pillars: 'standardization, assetization, and accessibility.' He explained what changes when redefined this way, focusing on where to integrate AI and where to keep it out.

"2-3 Weeks for One Survey"... The Three Walls Blocking Research
User research may sound grand, but its core is simple: asking users directly while making a game. It is the process of confirming whether content was fun, where users felt frustrated, and why they churned—not through guesswork, but through the users' own voices. The Nexon Game UX team conducts research on everything from games in early development to those with long-running live services.
The reason research is so important in gaming is that games are inherently non-linear experiences. Even with the same content, a casual user who plays for a few minutes a day and a hardcore user who dives deep into the game will have completely different experiences. The problem is that behavioral logs alone cannot fully explain these differences. If a large number of users drop off at a certain point, logs can confirm the fact that they left, but they won't tell you whether it was because the controls were clunky or the difficulty was too high. User research is what explains that 'why'.
Researcher Lee Se-wang summarized the difficulties of analyzing research results into three points. First is time. The number of voices to listen to keeps growing, but analysis time is scarce. Once a survey is received, the process of cleaning noise, coding, cross-tabulating, combining with behavior logs, statistical testing, and report writing must all be done sequentially. The more angles from which you view users, the longer this process takes, yet teams were constantly forced to finish within 2-3 weeks.
Second is judgment. It is difficult to grasp the meaning of figures without verification. For example, if hardcore users rate content satisfaction at 3.8 and casual users at 3.2, a 0.6-point difference exists. It is hard to judge through numbers and intuition alone whether this is a genuine difference in feeling or a statistical fluke. Proper verification requires statistical testing, which is difficult for designers or managers to perform on demand. As the number of items to check across groups, content, and periods grows, the testing workload increases, leading back to the time problem.
Third is knowledge loss. Even after analysis, insights often disappear rather than remaining in the organization. Results are usually buried in PPTs or feedback documents somewhere in a messenger app, leading to situations where teams unknowingly repeat the same questions that another department researched six months prior.

While there have been attempts to feed past reports into LLMs, the gaming domain has unique contexts; reports lacking that context are prone to hallucinations. Ultimately, hard-won insights fail to accumulate as organizational assets and remain locked in individual memories.
Lee emphasized that these three problems are interconnected. The deeper you try to analyze, the less time you have; even if you spend time writing a report, the knowledge is lost, making future decisions difficult again—a vicious cycle. He concluded that these problems must be solved together, not one by one.
Why not just feed data into a general-purpose AI? Lee noted that he reviewed this, but found two problems. First, when someone without a background in methodology or statistics uses general AI, the AI always provides a plausible-sounding answer.
Even if the wrong testing method is applied or necessary corrections for multi-item comparisons are skipped, the results look fine. The hurdle for the average user is having no standard to recognize when the AI is wrong. Second, even with experts, each person uses different preprocessing, aggregation standards, and prompts, leading to inconsistent results. The knowledge remains an individual asset rather than an organizational one.
There was also a structural problem in the analysis workflow. Because statistics and analysis require specialized training, the 'person who wants to ask' and the 'person who actually asks' were separated, often diluting the original intent of the questions.
Nexon's direction was not simple automation. It was to have the system handle complex methodologies so that people could focus on judgment, effectively making the person who wants to ask the one who actually does the asking.

"People are the Bottleneck"... What to Delegate to AI and What Not To
Lee began by addressing the concept of a 'bottleneck.' Elon Musk once said, "Humans will increasingly be out of the loop." Lee interpreted this not as human replacement, but as a question of 'where should humans be involved?' Computers exchange vast information in a blink, but human input/output speed is incomparably slower. No matter how fast the automation pipeline is, if a human is in the middle, the slowest speed becomes the bottleneck.
In legacy analysis using R or SPSS, the flow stopped whenever human judgment was required. Whether it was classifying response scales, reverse coding, mapping variables, or translating results into human language, a single pause would halt the entire pipeline.
Nexon's question was, 'What should we delegate to AI to eliminate these pauses?' The answer was to provide the AI with the complete context and procedures upfront, rather than having a human intervene for every judgment. If the system provides ▲necessary data, ▲processing guidelines, and ▲relevant context for every task requiring judgment, the AI doesn't need to guess, and the flow remains uninterrupted.

Roles were divided accordingly. AI handles tasks requiring language and light judgment: reverse coding, checking for typos/omissions, adjusting survey intent and options, augmenting context via desk research, and interpreting/summarizing complex results into natural language. AI excels at understanding and responding in human language.
Conversely, professional calculations were not delegated to AI. Areas requiring 100% accuracy—such as academic statistical testing, significance judgment, and data cleaning—are handled deterministically by a verified pipeline, ensuring the same data always yields the same result. This line was drawn because of AI's three limitations: ▲hallucinations, ▲weakness in precise numerical calculation, and ▲inability to reliably determine causality.

The Human's Place is 'Just Before the Report'

Where, then, should humans be? Lee started with two premises. First, AI's unreliable zones are clear. Even the latest reasoning models show a 10-33% error rate in fact-checking, which spikes in specialized domains. Recent papers confirm that eliminating hallucinations is structurally impossible. Second, humans possess something AI cannot: tacit knowledge accumulated through hundreds of research sessions and playtests that is hard to explain in words. AI cannot have this 'gut feeling,' but it can multiply the productivity of a person who does.
The key is not model performance, but how judgment is distributed between human and AI. The true essence of 'human-in-the-loop' is removing humans from segments where no judgment is needed to increase speed, and re-introducing them at points where only human judgment matters. He identified the 'pre-report' stage as the primary spot. Before the AI finalizes the report, the researcher reviews segment results to decide where to focus, which segments to include, and what to dig deeper into.
Based on this, Nexon established four design principles applying the 'Garbage In, Garbage Out' adage. First, do not use AI for verified areas; use deterministic pipelines. Second, AI interprets, but humans make the final judgment. AI suggests candidates and evidence, but the human decides.
Third, all AI interpretations must cite the structured data used as evidence, allowing for human verification at any time. Fourth, incoming data is stored without loss. Every step—from context and preprocessed data to results and AI interpretations—is fixed in a searchable, linkable format.
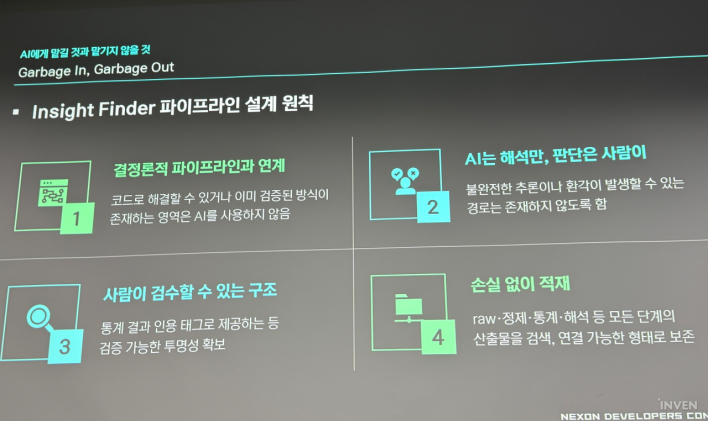
"Numbers by System, Words by AI"... Standardization, Assetization, Accessibility

The core of the 'Insight Finder' system flow is standardization, assetization, and accessibility. Together, these allow verified analysis that once took experts days to complete in a single execution. In the actual workflow, humans only handle the beginning and the end: registering the survey and defining the goal, then reviewing the results to decide what goes into the report. The system and AI handle everything in between.
Standardization is the step where AI is provided with refined information so it doesn't get lost in a narrow context. The keys are 'consistency' (same data, same result), 'comparability' (standardized processing allows comparing different results), and 'information density' (compressing thousands of raw responses into key statistics). A deterministic pipeline designed by experts handles this automatically, turning a multi-day data cleaning task into a single-run process. All test results are stored as structured data, and the AI simply interprets those numbers into words. Lee summarized this as: "Numbers by the system, words by the AI."
Assetization is the step of preserving every intermediate result created during analysis. It is not just storage, but a process of making data usable for the organization and linkable by other departments, pulling knowledge out of personal folders and messengers. This assetization enables the next step: 'anyone can ask.'
Accessibility is the part Lee emphasized most. Previously, one needed an 'interpreter' (an analyst) to look at data, requiring requests and waiting. Now, anyone can ask questions directly in natural language. Designers, directors, and PMs can each query the same data from their own perspectives.

100 Users in 4 Months Without Promotion... "3 Weeks to 30 Minutes"
Lee then explained real-world examples of 'Insight Finder' in action.
The workflow is simple. User data is collected via the official 'Nexon First' platform, and clicking 'Analyze' on a survey moves it to Insight Finder with one click. After selecting the analytical angle, data processing, statistical analysis, and AI insight extraction begin. Through custom segments, users can attach in-game logs or use segments/data accumulated by the Game UX team to analyze data not even collected in the current survey.
As a result, an AI report is ready within 30 minutes of survey completion. The structure moves from the big picture to details: overview, key issue summary, and detailed analysis. Every sentence includes evidence, and the data used for AI interpretation is always cited, accessible via pop-up. Statistically significant differences are visualized in green and red, allowing even those without statistical expertise to identify key points at a glance.
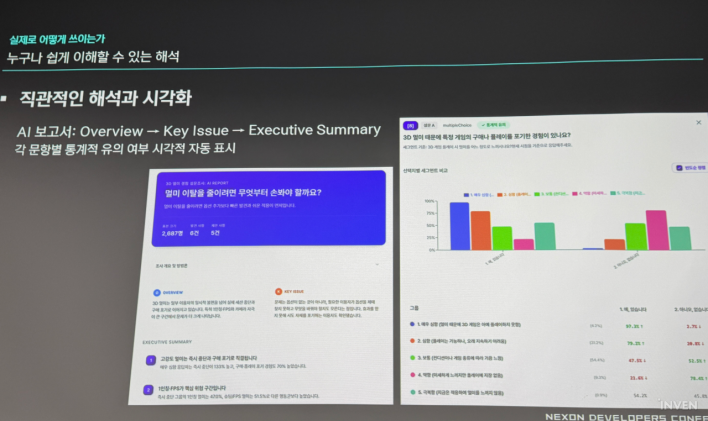
He added that the system's true power lies in its refinement over time. It connects data in three ways: 'Time Trends' to see how 2024 issues evolved by 2026; 'Cross-Survey Analysis' to compare how users who use Discord voice chat versus those who don't evaluate collaborative content without needing to ask the same questions; and 'Integration', where large-scale user trend/preference surveys collected by the Game UX team are attached to individual surveys. Today's report becomes the material for a completely different analysis six months later, accumulating as an asset rather than being consumed once.
Internal organizational response is also notable. Lee revealed that without any promotion or internal announcements, the tool spread voluntarily to over 100 people across various game teams in less than four months.
The research method itself has changed. Now, they look at users from an average of 19 angles per survey. Previously, they were lucky to look at three or four aspects within the 2-3 week deadline; since adoption, they look more often and more deeply.
The time saved using Insight Finder was listed as approximately 9k hours over four months on the slide, but Lee noted, "Checking again on the day of the presentation, it exceeded 12k cumulative hours, equivalent to about five years of work." He clarified that this is a conservative estimate based on saving 3 hours per segment analysis, assuming a senior researcher uses AI without limits, rather than a simple comparison to the 3-week legacy workflow.

"Models Will Standardize, Assets Will Not"
What Lee truly wanted to create with Insight Finder was not just automation or time-saving. It was to enable anyone to view, analyze, and understand users from dozens or hundreds of angles as much as they want. He stepped back to point out that everyone is currently using the same AI models, and the models themselves are rapidly standardizing.
Where, then, does true competitiveness come from? His conclusion is that unique assets—analyzing and understanding our users in our own way—make the difference. Future AI success will not depend on model gaps or the adoption of the latest tech, but on how well one has assetized unique data and built a system that continuously accumulates unique context.
Future directions are summarized by the expansion of Insight Finder. He identified the first step as making the start of a survey easier based on usage data, allowing anyone who wants to research from a specific perspective to set up a draft and secure responses immediately.

Furthermore, they are considering 'AI Panels,' a hot topic in the research industry. The concept is that if you understand users deeply enough and have the context, you can ask an AI persona instead of real users. Nexon is reviewing a pipeline that compares results from real users with AI persona responses; if the persona responds as well as real users, they can even conduct interviews with the persona to ask questions missed in the survey.
Concluding his presentation, Lee summarized that his work was ultimately about restoring the proper place for humans, systems, and AI. The system handles verified statistics deterministically, AI interprets and communicates, and humans focus on the most important task: 'what to ask.' Through the synergy of standardization, assetization, and accessibility, 3 weeks became 30 minutes.
However, he repeatedly emphasized that the core is not the shortened time, but the structure where context accumulates without disappearing, allowing anyone to utilize research. Analysis once done by a few experts becomes an organizational capability, and as the system tracks what people were curious about, it suggests more accurate future research. It is a virtuous cycle where good research leads to better questions, which in turn lead to even better research.
Lee ended his presentation by saying, "I hope this story serves as a small hint for everyone as you contemplate AI pipelines or AI transformation in your own roles."


Sort by:
Comments :0





