Anthropic officially released its new AI model, Claude Opus 4.8, on the 28th (local time). This comes just 42 days after the release of its predecessor, Opus 4.7.
| 📒 | - Anthropic Launches Claude Opus 4.8... 42 Days After 4.7 - Emphasis on 'Honesty' Over Benchmarks; Probability of Overlooking Code Defects Reduced Fourfold - 8.5%p Improvement in Terminal-Bench Over 4.7... Still Trails GPT-5.5 |

Opus 4.8 marks the fastest update cycle for any of Anthropic's new models. Given this rapid release pace, the update is viewed more as an incremental improvement than a major leap. While Anthropic introduced Opus 4.8 as the most powerful model currently available to the public, it also noted that 'users will find it a modest but clear improvement over the previous version.' The API is available for immediate use, and pricing remains identical to the 4.7 version.
Anthropic’s primary focus is not on benchmark scores, but on the model's 'honesty.' For instance, the model is now less likely to make unsupported claims or confidently assert that a task is complete when the evidence is thin. Anthropic stated that the probability of the model failing to identify defects in its own code has decreased by approximately four times compared to version 4.7.
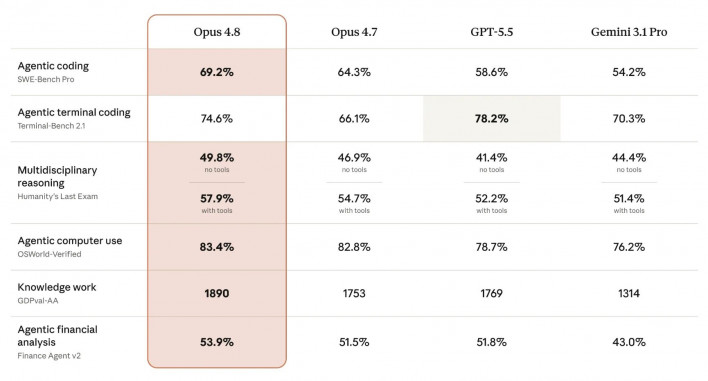
In terms of performance, the gains in coding are particularly notable. Opus 4.8 scored 69.2% on the notoriously difficult 'SWE-bench Pro' coding benchmark, surpassing the 64.3% achieved by 4.7. It also outperformed both GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%) on the same test.
However, in 'Terminal-Bench 2.1,' which measures coding in terminal environments, GPT-5.5 leads with 78.2%, ahead of both Opus 4.7 (66.1%) and Opus 4.8 (74.6%). GPT-5.5's internal measurement using the Codex CLI harness was 83.4%.
While Opus has outperformed GPT-5.5 in most benchmarks, its failure to gain an edge in the terminal domain—both in 4.7 and now 4.8—is significant. The shell/CLI terminal environment is where coding agents are most frequently deployed and is the area most often encountered in practical work. In particular, OpenAI is aggressively targeting the CLI coding tool market with Codex, directly competing with Claude Code. In this sense, the terminal benchmark serves as a scorecard for the most critical battlefield in the industry.
Nevertheless, Anthropic's 8.5%p boost in terminal benchmark performance compared to 4.7 demonstrates its determination to gain an advantage in terminal environments. With OpenAI performing well behind its Codex model, it remains to be seen whether Anthropic can retain developer interest with Claude Code.
Meanwhile, the company also announced plans to release a new, even more intelligent model. With a select few institutions already using the 'Mythos' preview for cybersecurity purposes, Anthropic added that it plans to release a Mythos-class model to the public within weeks, following the development of necessary safety guardrails.
![]()
- Seungjin "Looa" Kang
- Email : looa@inven.co.kr






Sort by:
Comments :0