

Topic: There's No Way I Can Create a Pretty Girl's Voice, No Way! (※Wait, It Wasn't Impossible?!) - A Journey into Developing Korean/Japanese TTS Models Using SBV2 Open Source Speaker: Kim Myeong-ji, Part Leader, Yggdrasil ML Team, IO Division, Nexon Games Field: Artificial Intelligence Recommended for: Those curious about the process of expanding open-source models for multilingual support
Tags: #TTS #Model Porting #G2P
[🚨 Lecture Topic] In this session, we will explore the Japanese-based SBV2 model and detail the technical solutions and trial-and-error processes involved in adapting it for a Korean environment. This includes implementing Korean G2P logic, porting the BERT Korean model, and automating data preprocessing and emotion labeling using other AI models like LLMs.
In the content industry, Text-to-Speech (TTS) is now a familiar technology. Beyond simple text-to-audio features like those in e-book readers, it is frequently used in video production, such as on YouTube, as an alternative to manual voice recording. The gaming industry is no exception; even games with star-studded voice acting casts are utilizing TTS for various reasons.
A prime example is Nexon Games' 'Blue Archive.' Arona, the game's mascot, calls the player by their name (ID) in-game—a feature implemented using TTS technology rather than pre-recorded lines. It serves as a device to enhance player immersion.
So, what efforts did Nexon Games make to implement such natural-sounding TTS? The second-day NDC session, 'There's No Way I Can Create a Pretty Girl's Voice, No Way! (※Wait, It Wasn't Impossible?!) - A Journey into Developing Korean/Japanese TTS Models Using SBV2 Open Source,' shared the development process and the challenges faced along the way.
Why did the IO team invest so much in TTS? The key is 'immersion'

In modern subculture games, the participation of famous voice actors is no longer a novelty. Yet, despite having a massive cast of voice actors, 'Blue Archive' is unusually dedicated to developing its own TTS technology.
Kim Myeong-ji explained, "We did it to make players feel like they are truly interacting with the characters."
No matter how passionate a voice actor's performance is, there is a limit to pre-recorded audio. TTS, on the other hand, can generate new speech in real-time if the right conditions are met. Arona calling the player by name is a perfect example.
However, the IO team's goal went beyond just calling out names. They aimed to move past the 'robotic' delivery of existing TTS, which lacks emotion, and instead implement a natural voice that captures the unique personality of the character Arona.
The first step was selecting the optimal TTS model. With many open-source options available, the verification process was difficult. The IO team compared and analyzed each model based on three criteria: character identity, emotional expression, and naturalness. While all were important, the team placed the most weight on naturalness, believing it would be the deciding factor for immersion. After evaluating aspects like breathing between words, long vowel expression, pitch-based accents, and noise levels, they ultimately adopted SBV2 (Style - Bert - VITS2).

The selected SBV2 performed exceptionally well. Japanese is a language where word meaning changes based on long vowels and accents. For example, 'yuki' (ゆき) means snow, while 'yuuki' (ゆうき) means courage. Similarly, 'ame' (あめ) can mean rain or candy depending on the pitch and accent placement.
While SBV2 could analyze sentences and understand context to generate natural pronunciation, there was one problem: it did not support Korean. Consequently, the development team analyzed the SBV2 learning structure and set out to build their own Korean learning model.
If it doesn't exist, build it! - Building a Korean learning model
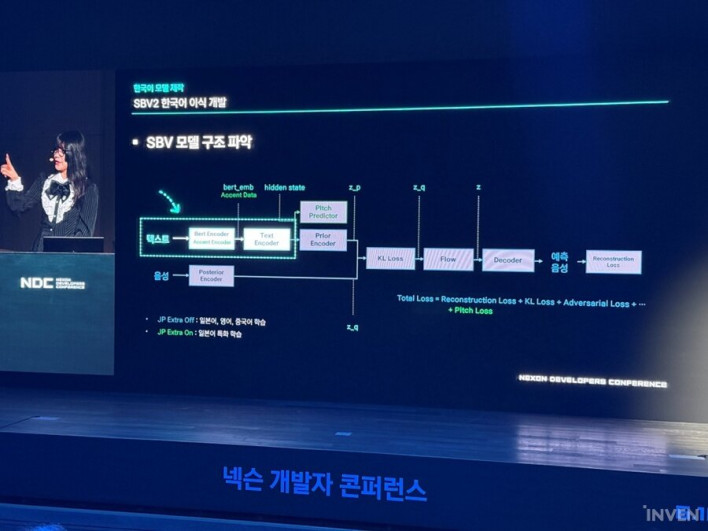
In the process of building the Korean model based on SBV2, the team first boldly removed Japanese-specific features, such as morphological analysis for Kanji and Japanese accent processing. They then added functions to convert Korean characters into actual phonetic forms.
Next, they replaced the BERT model with a Korean version. The BERT model plays the role of distinguishing meanings based on context—for example, determining whether the word 'il' (일) refers to the number 1, labor, or a date.
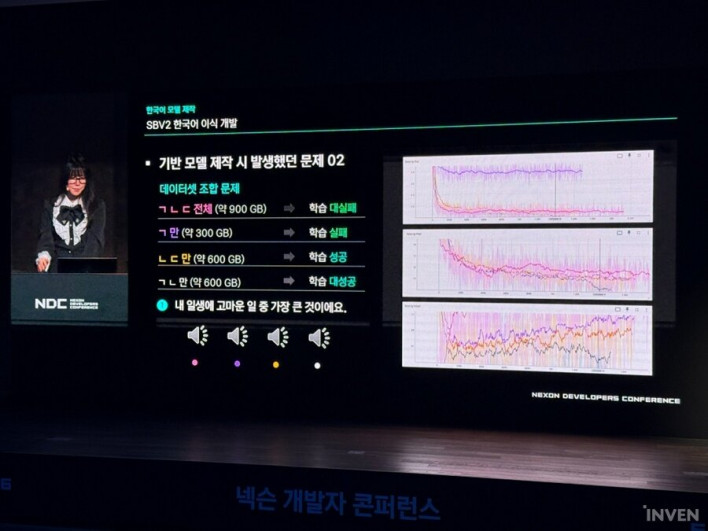
After building the Korean learning model, they entered the full-scale training phase. This, too, was not smooth. While training with approximately 600GB of voice data, an overfitting problem occurred where the balance between the generator and the discriminator collapsed.

The goal was for the generator and discriminator to learn naturally by comparing results, but the discriminator was too 'smart' from the start, marking all of the generator's early outputs as incorrect. As a result, the generator could not improve sufficiently.
To fix this, the team artificially adjusted the learning speeds, allowing the generator to reach a certain level of proficiency before the discriminator began its training. This ensured they maintained a healthy competitive relationship, allowing both to improve in performance.
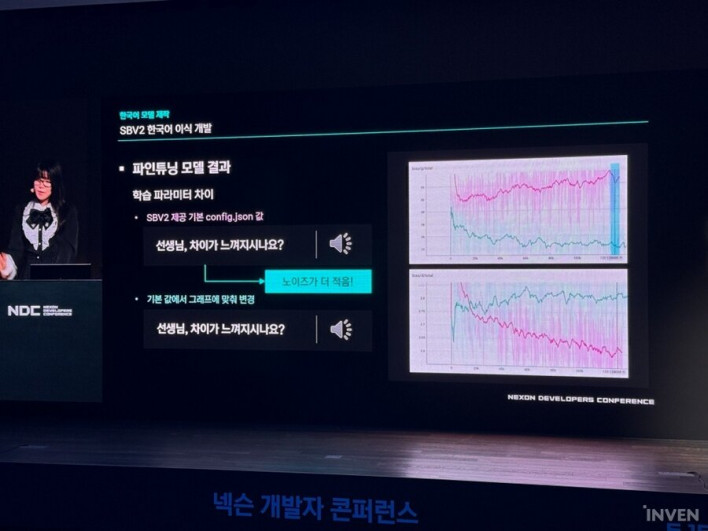
Another issue was noise. During the base model development, severe noise occurred in data containing certain phonemes, particularly 'ㄷ' (d/t), leading to quality degradation.
The team's solution was surprisingly simple: they determined that it was more effective to boldly exclude the problematic data rather than trying to use the entire dataset. By removing that data, they were able to establish a stable learning environment.
Future Tasks - Corpus construction and establishing quantitative/qualitative evaluation systems
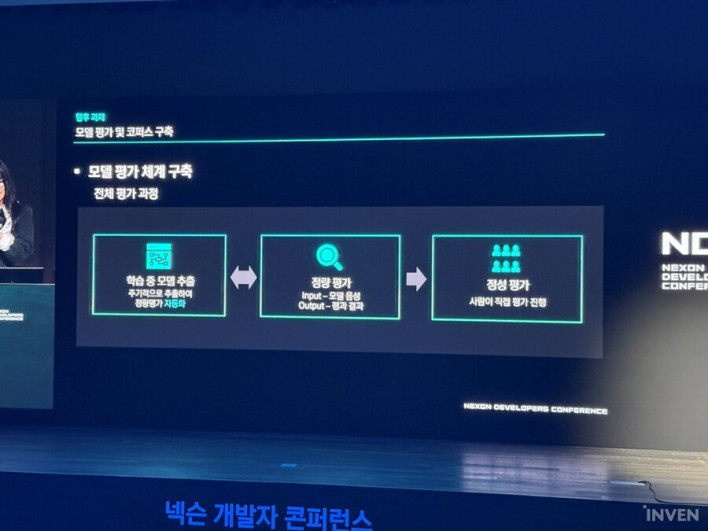
Kim Myeong-ji identified the establishment of systematic quantitative and qualitative evaluation systems and corpus construction as future tasks.
Currently, the primary method is listening to and evaluating TTS results manually, but the plan is to introduce a quantitative evaluation system that automatically assesses models at regular intervals. The goal is to further improve quality by implementing a multi-stage verification process where only models that pass quantitative evaluation proceed to qualitative assessment.
They also plan to focus on building a corpus. While a dataset generally refers to learning data combining audio and text, a corpus refers to a collection of data systematically designed for a specific purpose.

Kim explained, "Currently, the Korean-based model sometimes struggles to naturally express punctuation like '~' or '...' or certain sibilants. We plan to improve these issues through future corpus construction."
Meanwhile, Nexon Games announced that they plan to release their SBV2 Korean model as open source in the near future. The intention is to help develop the ecosystem by allowing more developers and researchers to utilize and improve upon it.
In closing, Kim emphasized, "Making a TTS speak is not difficult in itself. What matters is not just having it speak, but making the user feel immersed in the character." She concluded the lecture by expressing her ambition: "We will continue to work toward creating even more realistic voices without losing sight of that goal."


Sort by:
Comments :0





